The Clean Architecture Breakdown

The concept of the Clean Architecture could be somewhat nebulous for many of us as we learn structures such as MVC, MVP, MVVM, etc. Therefore, I read, studied, and contemplated trying to apprehend the concept better. Today, let me share my findings with quotes from Robert C. Martin.
from his blog
TL;DR ::before
First, I’d like to state that this is how I interpret the concept and reflected on real development occasions, and not the absolute truth about how one should perceive it. If any of you have profound insights on this topic, please share your valuable knowledge and experiences. The world always has so many engineers searching for better ways.
A clean and explicit dependency flow is the key
According to the blog by Robert C. Martin, this “Dependencies Rule” is the most important concept.
We don’t want anything in an outer circle to impact the inner circles.
This rule is about keeping the dependency flow to make sure “…source code dependencies can only point inwards.” In other words, the inner layer cannot know about the outer layer. If we try to apply this to MVP, models should not know about view components or make changes to them.
On the other hand, the data structure of models should not be changed for the convenience of the views. The models are abstractified business logic, and the data structure should be true to the domain. The views sometimes need to transform the received data, and a Presenter or ViewModel comes in for this purpose. They are the ones that are responsible for keeping the data flow and transforming the data for the views.
Next, let’s talk about these layers.
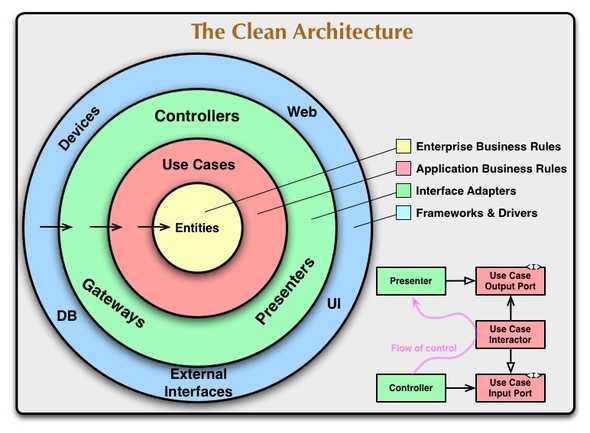
The Four Layers
As you can see on the chart, the Clean Architecture is comprised of four layers. R.C. Martin mentions that there is no need to limit the layers to four, but that would be the inner breakdowns of each layer in my opinion.
Here are the four layers.
Entities
This represents “…Enterprise wide business rules…” which rarely change. This layer will not be affected or changed by application feature definitions. For example, Client, Transporting Process, Recipient, or Accounting in the transport business, etc are critical and significantly important concepts to fulfill the domain business logic.
However, we are not always building core systems for business that requires so much care for these. So if we are launching a new service, we can focus on entities/concepts that are most crucial for shaping the service or application. For example in Twitter, tweets and users would be categorized to this layer, and UI/UX and other features would belong to the outer layer.
Use Cases
This is the layer for “…application specific business rules.” We put detailed but not UI-related features and define specific business processes and flow here. This layer will not be influenced by Entities, UI, or database. However, it would be affected by the application’s feature definition changes. Logics and functions that handle the entities in more specific ways would be put in this layer, and perhaps it would be easier to grasp the image with examples where it’s combined with the interfaces in the next chapter.
Interface Adapters
In some other general coding philosophy/architectures, this layer could be called ViewModel, Presenter, Controller, etc. Its responsibility is to convert raw data into entities, or data shapes that are suitable for use cases and UI components. We often find the data structure in a database does not match the entities (e.g. impedance mismatch). So this layer takes care of the conversion.
For example, if well-normalized user data is stored in an RDBMS, most likely we cannot use these table definitions as entities, and vice versa. A user entity would be usually the result of merging these multiple tables with a query in OOP (e.g. user and membership level etc). Modules like ORM or DAO are the ones that belong to this layer and solve this type of data structure mismatches. By knowing that the data structure and entity expressions don’t necessarily match, we can raise the independence level of each layer and lower the degree of coupling.
This layer is very important for keeping Entities and Use Cases in bubbles and not letting the outer layer influence them. Database queries or decisions of what data would be displayed on the UI should all be done in this layer. Entities and Use Cases should never see the ever-changing world outside of the bubble as we develop the application.
Frameworks and Drivers
This is the outer rim of the architecture, where components like UI and database are subject to constant changes. Because of its unstable nature (as UI and data would suffer from feature definition changes), we have to isolate them as much as possible so that we can minimize the influence of these changes on the inner layers. Therefore, components on this layer can only speak to the interface adapters which are the adjacent layer so that they will not affect the core layers.
Layers and Abstraction
R.C. Martin describes the structure as “…you move inwards the level of abstraction increases.” This is easier to understand when we imagine an application by looking at the layer chart. The UI and the data are the most specific components, and the entities are the most abstract. As people who are familiar with OOP would imagine quickly, “Martin” is the most specific data and it would eventually become a “User” entity if we keep abstractifying.
Use cases have more specific behaviors or functions than the ones of entities. You might think we are to delegate all entity class methods to use cases. However, we still need to split methods based on their abstraction levels, so there is no absolute answer.
For instance, in the abstraction level of a User entity, we keep changeName(), usePoint(), or other methods that only require local resources and complete internally. Meanwhile, a UserUseCase could have methods like buyItemWithPoints() which calls the User’s usePoint(). Then, this flow completes by calling an interface of the outer layer to convert the logical user data into physical data, and a database driver saving the data. Of course, we can imagine some Presenters notifying the data changes to the UI at the same time.
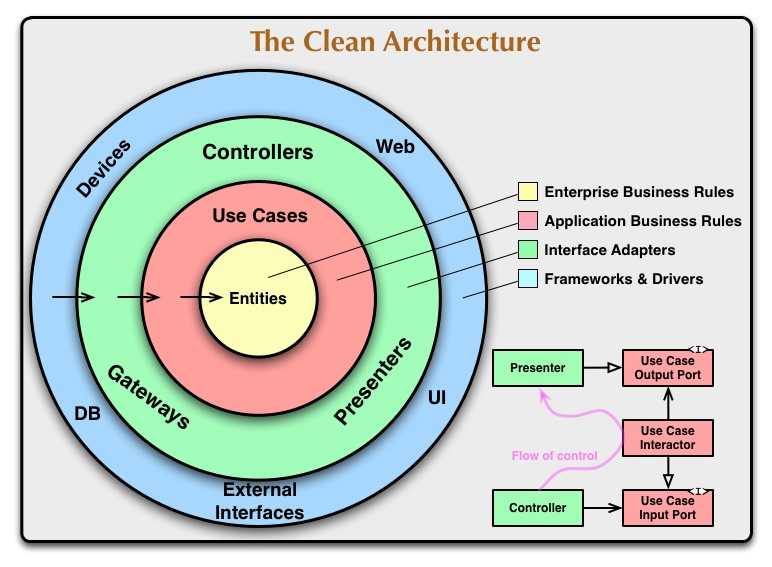
Interfaces keep the clean dependency direction
We might feel like “it’s actually simpler than I thought” after reading about the dependency relationships. However, we will have to face some contradictions when we develop an application in real life. Remember, the absolute rule of the dependency relationships is that the reference is only allowed from the outer to the inner, and the inner layer cannot have references to the outer layers.
As I mentioned that the use case “…calling an interface of the outer layer…”, interface adapters are the ones that make it possible to have reversed-directional controls while keeping the relationship.
We take advantage of dynamic polymorphism to create source code dependencies that oppose the flow of control so that we can conform to The Dependency Rule no matter what direction the flow of control is going in.
The “dynamic polymorphism” here is the runtime polymorphism, which refers to Java interfaces that would not know what operations would be executed until runtime. We can minimize the inner layer’s influences on the outer by using well-abstractified interfaces. If we lower the abstraction level of use cases or entities by giving unnecessary information or authority to them, there would be more chances of unexpected vulnerability and difficult adjustment caused by feature definition changes.
Data passed between the layers
When we pass around data between the layers, we should not use the data structure of database tables, or a “RowStructure” as he calls. This data structure is not-optimized data which could be a JSON array or entities from databases or APIs.
Again, entities should not know the data structure of a database. If entities knew the raw structure, use cases and interfaces would also know. Meaning, if any change occurs to the database in such an architecture, all the layers would be affected.
The golden rule is to convert data into a DTO which contains minimal information when we pass the data across the layers. This will protect the explicit dependency relationship structure which is the biggest advantage of the Clean Architecture.
For example, many database frameworks return a convenient data format in response to a query. We might call this a RowStructure. We don’t want to pass that row structure inwards across a boundary. That would violate The Dependency Rule because it would force an inner circle to know something about an outer circle.
TL;DR ::after
While many frameworks are based on the MVP or MVC coding philosophy, I assume there are not a few engineers who are not feeling so clear about the Clean Architecture. If you are one of them and feel like you “understand it better now”, it was worth writing this article.
I was confused by the circular structure at first. We are familiar with the top-to-down ones, but when we get stuck with the idea of “database being the bottom layer and UI being the top”, this philosophy is hard to grasp. Therefore, I would suggest looking at it as “abstraction layers” and compare to “specific layers” of MVP since this is all about the level of abstraction.
Just like a lantern on a dark street, I feel like this idea of dividing by abstraction levels would guide us through when we cannot decide which component should take which operation.